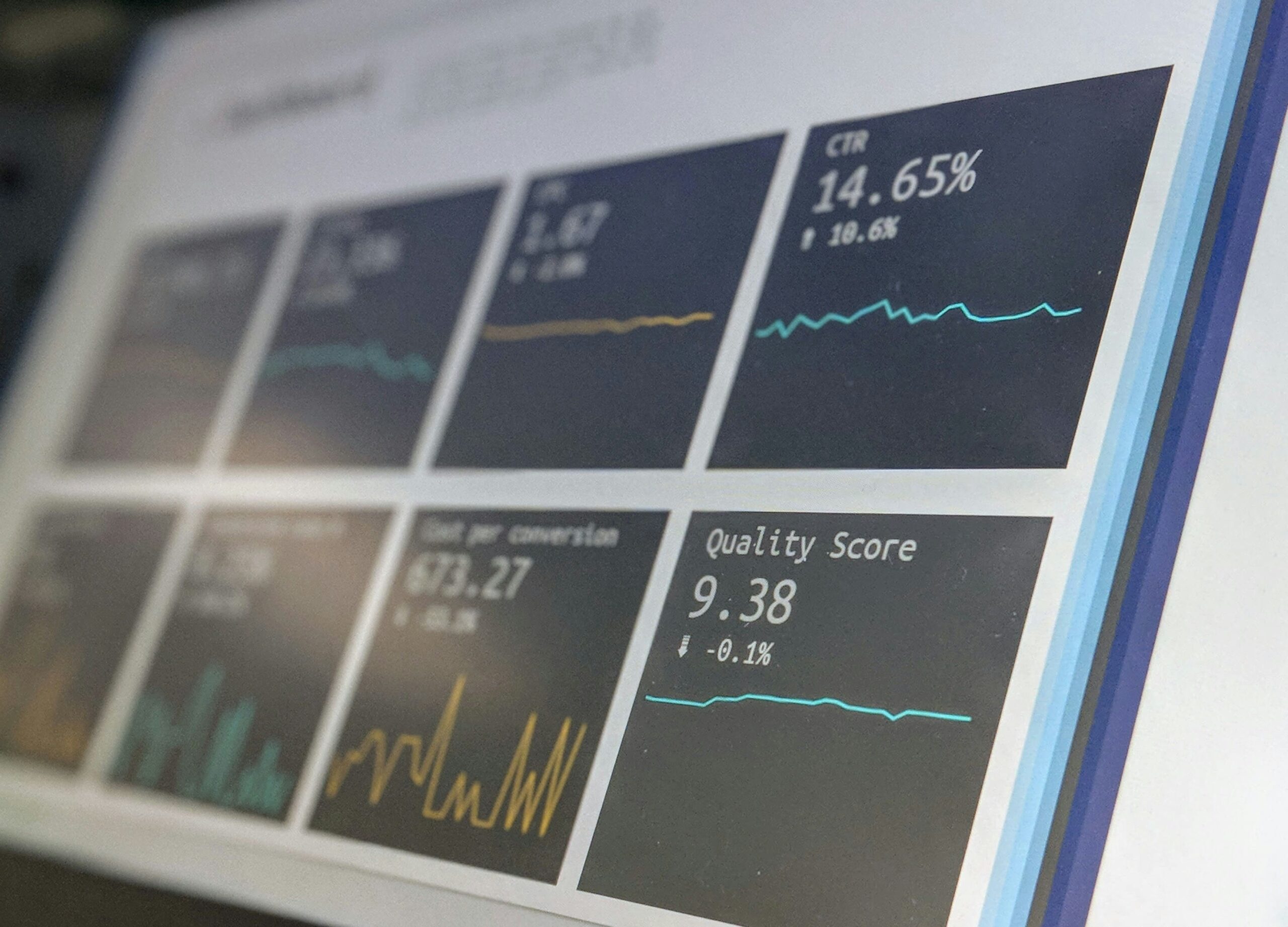
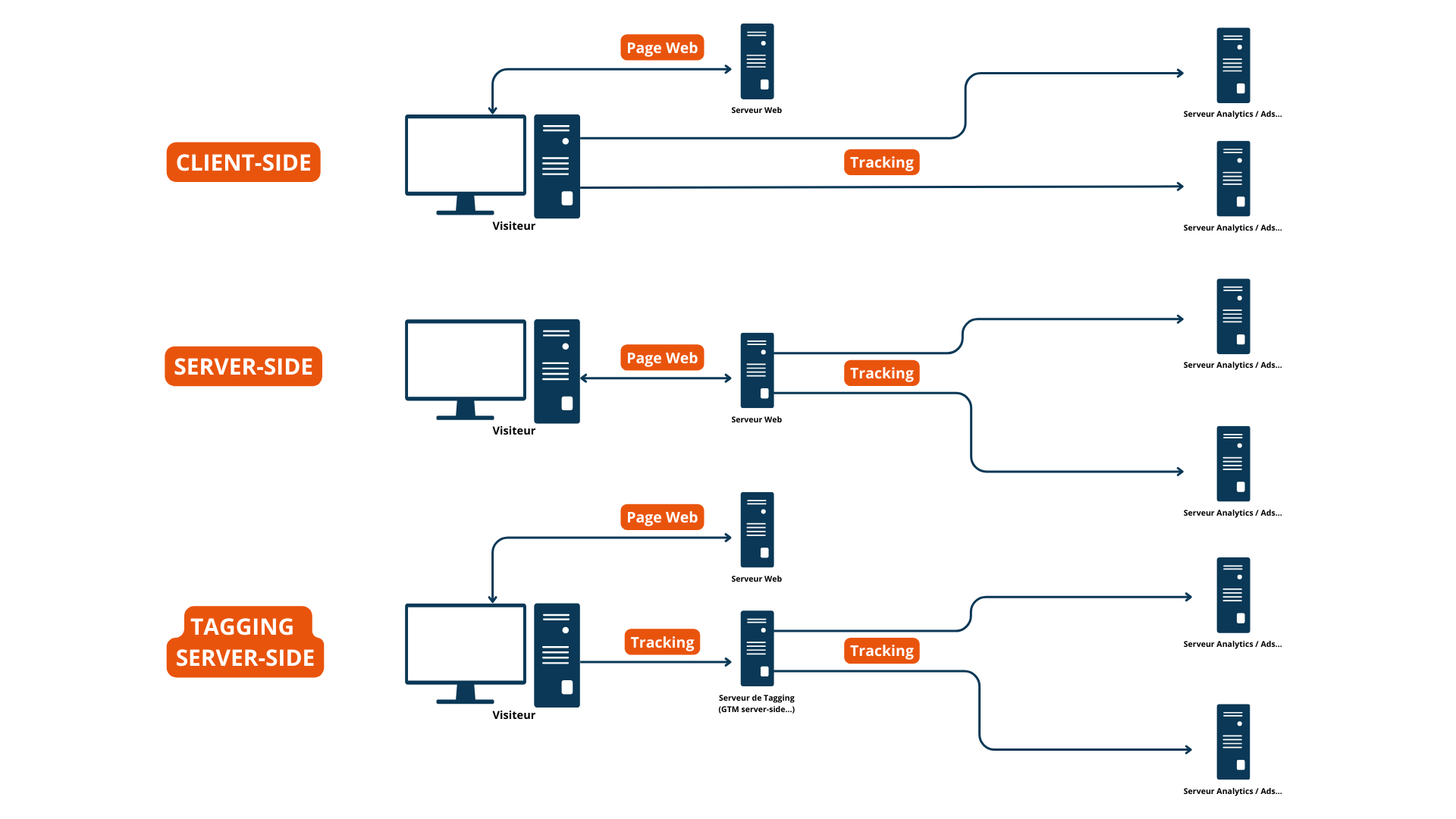
Plus on ajoute de tags tiers (services analytics, régies publicitaires, réseaux sociaux, etc) dans le code de source d’une page, plus on affecte potentiellement leur temps de chargement. Avec le Server-Side, le tracking passe uniquement par des serveurs, ce qui permet de réduire la charge côté client et garantit donc un temps de chargement plus rapide.
Exemple : si vous intégrez sur votre site 7 tags de solutions tierces, alors en mode Client-Side, vous générez 7 requêtes du navigateur de l’utilisateur vers les serveurs des acteurs tiers. En mode Server-Side, vous n’avez plus qu’une seule requête mutualisée car la répartition des données se fait depuis le serveur web.
De plus, si vous réduisez le nombre de balises, vous diminuez les risques de bugs d’affichage et autres dysfonctionnements techniques qui peuvent impacter à terme l’expérience utilisateur.